with Low-Cost Hardware
Abstract. Fine manipulation tasks, such as threading cable ties or slotting a battery, are notoriously difficult for robots because they require precision, careful coordination of contact forces, and closed-loop visual feedback. Performing these tasks typically requires high-end robots, accurate sensors, or careful calibration, which can be expensive and difficult to set up. Can learning enable low-cost and imprecise hardware to perform these fine manipulation tasks? We present a low-cost system that performs end-to-end imitation learning directly from real demonstrations, collected with a custom teleoperation interface. Imitation learning, however, presents its own challenges, particularly in high-precision domains: the error of the policy can compound over time, drifting out of the training distribution. To address this challenge, we develop a novel algorithm Action Chunking with Transformers (ACT) which reduces the effective horizon by simply predicting actions in chunks. This allows us to learn difficult tasks such as opening a translucent condiment cup and slotting a battery with 80-90% success, with only 10 minutes worth of demonstration data.
Teleoperation System
We introduce ALOHA 🏖️: A Low-cost Open-source Hardware System for Bimanual Teleoperation. With a $20k budget, it is capable of teleoperating precise tasks such as threading a zip tie, dynamic tasks such as juggling a ping pong ball, and contact-rich tasks such as assembling the chain in the NIST board #2.
Learning Algorithm
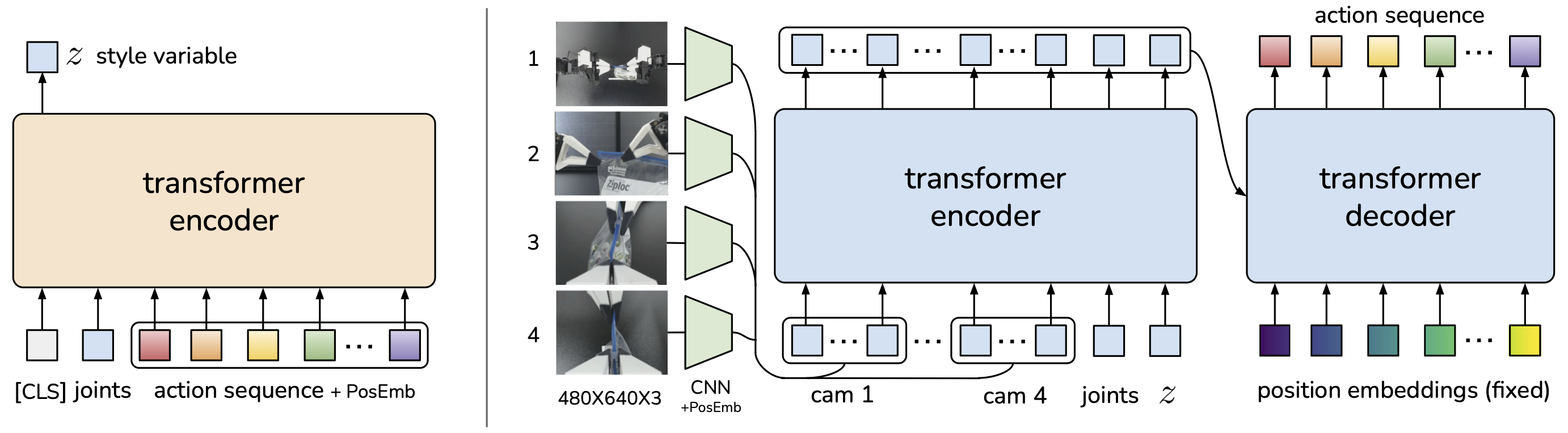
We introduce Action Chunking with Transformers (ACT). The key design choice is to predict a sequence of actions ("an action chunk") instead of a single action like standard Behavior Cloning. The ACT policy (figure: right) is trained as the decoder of a Conditional VAE (CVAE), i.e. a generative model. It synthesizes images from multiple viewpoints, joint positions, and style variable \(\mathcal{z}\) with a transformer encoder, and predicts a sequence of actions with a transformer decoder. The encoder of CVAE (figure: left) compresses action sequence and joint observation into \(\mathcal{z}\), the "style" of the action sequence. It is also implemented with a transformer. At test time, the CVAE encoder is discarded and \(\mathcal{z}\) is simply set to the mean of the prior (i.e. zero).
The videos below show real-time rollouts of ACT policies, imitating from 50 demonstrations for each task. The ACT policy directly predicts joint positions at 50Hz with a fixed chunk size of 90. For perspective, the episode length is between 600 and 1000. We randomize the object position along the 15cm white referece line for both training and testing. For the following four tasks, ACT obtains 96%, 84%, 64%, 92% success respectively.
Reactiveness
ACT policy can react to novel environment disturbances, instead of only memorizing the training data.
Robustness
ACT policy is also robust against certain level of distractors, shown in videos below.
Observations during policy execution
We show example image observations (i.e. the input to the ACT policy) at evaluation time. There is a total of 4 RGB cameras each streaming at 480x640. Two of the cameras are stationery and the other two are mounted on the wrist of robots.
?
Website template: Allan Zhou